Machine learning model testing and model validation are both important steps in the development of a machine learning model.
Model Validation is the process of evaluating the performance of a model on a separate validation dataset during the training phase. The goal of validation is to estimate how well the model is likely to perform on new, unseen data and to ensure that the model is not overfitting the training data. Validation is an iterative process that is performed multiple times during model development to fine-tune the model.
In general, testing is performed after the model development is complete, and it serves as a final check to ensure that the model is ready for deployment. Validation, on the other hand, is performed during model development, and it is used to make decisions on how to fine-tune the model.
Testing is important to ensure that the model is ready for deployment, while validation is important to ensure that the model is generalizing well to new data and is not overfitting the training data.
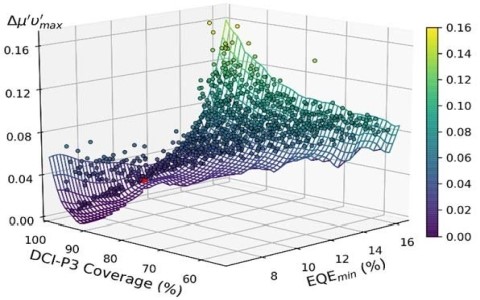
The choice of validation technique depends on the specific problem being solved and the size and nature of the dataset. In general, it is a good idea to use multiple validation techniques to get a more complete picture of the performance of the model. Some of the common techniques are:
Time Series Validation: This technique is used for datasets that have a temporal component. The dataset is split into training and validation sets based on time, with earlier data used for training and later data used for validation.
Leave-One-Out Validation: This technique involves using all but one observation for training the model and validating its performance on the left-out observation. This process is repeated for all observations in the dataset.
Stratified Sampling: This technique is used to ensure that the dataset is representative of the population being studied. The dataset is divided into strata based on some characteristic (such as age, gender, or income), and a random sample is selected from each stratum.
Bagging: This technique involves resampling the dataset with replacement to create multiple samples, each of which is used for training and validation of the model. The average performance metric is calculated over all resamples.
We have a pool of experienced Engineers and Managers. We take care of your ML Model Validation challenges. We setup your teams for you. Be it Project Consultancy, Agile Team Management, Software Testing, Machine Learning Models, Product Development or just simple software development. We provide A-Z of Data Science SDLC services, the complete package.
Having the working background from DevOps, Automation and as Solution Architect, we will streamline all your Data Science processes.
Our hourly rate ranges between $15 - $60 per hour for project based work.Our primary focus is all Data Science related areas namely AI, BI, Big Data and ML.
We're happy to provide you with more details about our Consultancy Services. Let one of our representative get back to you.
Building Competent Teams Across 15 Different Areas. Check our website for full details or drop us a query